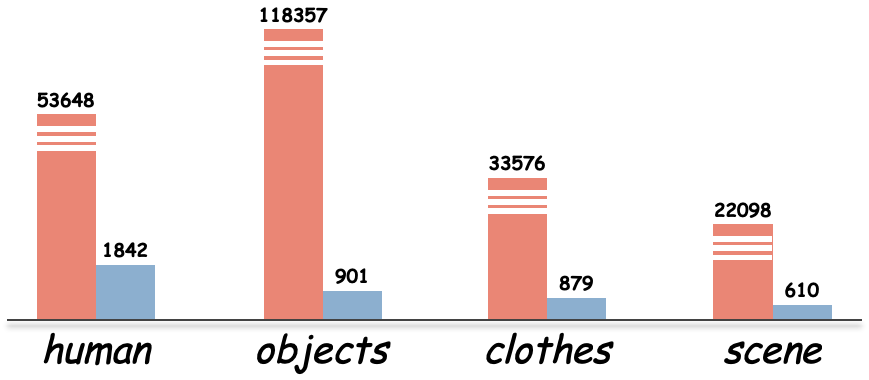




 Enabling Community Models with MICo Capability
Enabling Community Models with MICo Capability
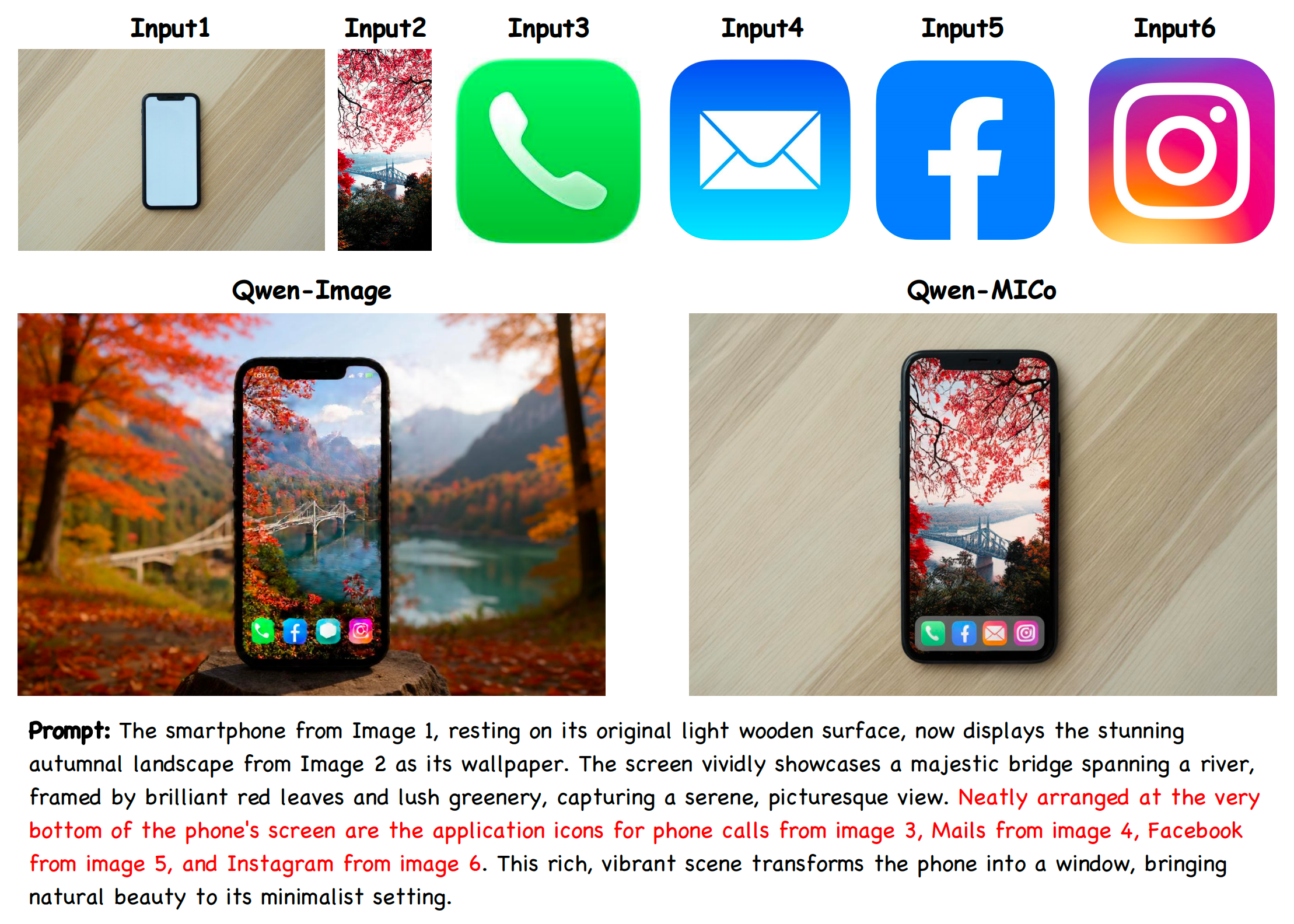
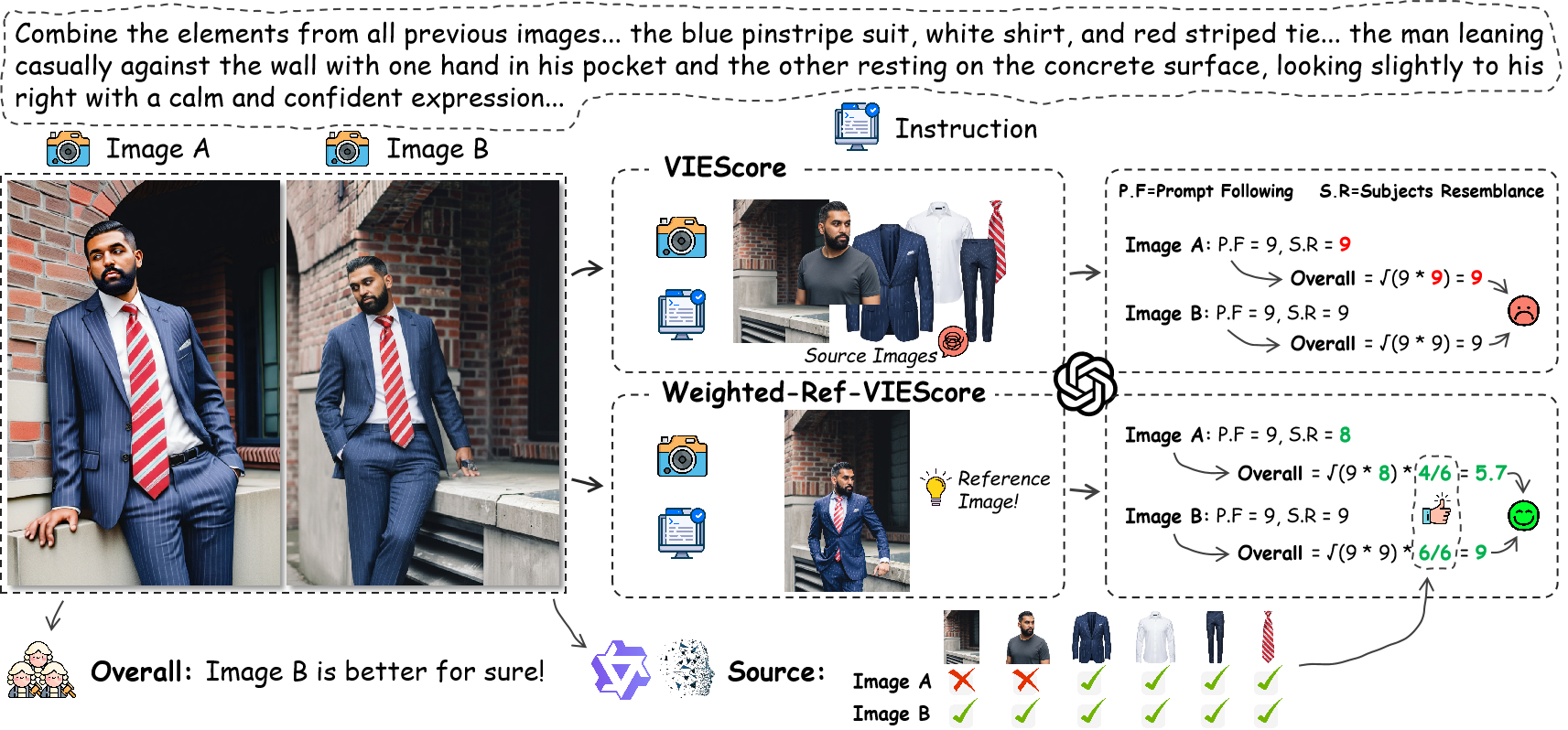
 MICo-Bench Qualitative Results
MICo-Bench Qualitative Results
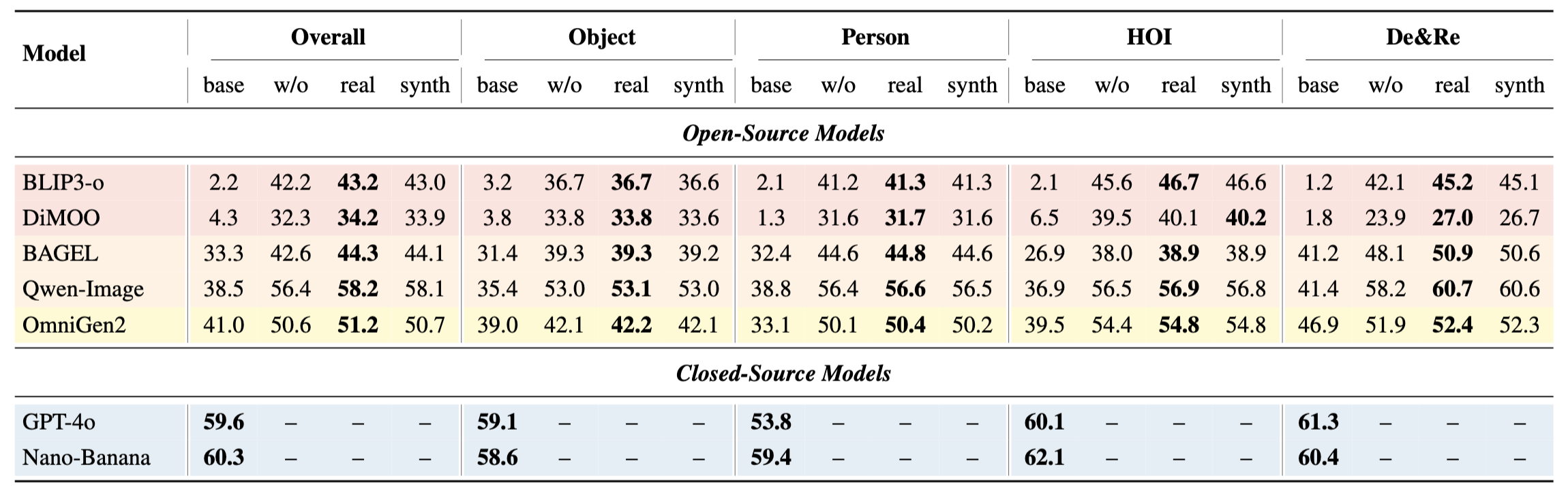
Performance comparison on MICo-Bench across different open-source and closed-source models: “base” denotes the original model; “w/o” indicates fine-tuning without the De&Re task; “real” and “synth” correspond to fine-tuning with real and synthetic compositions from the De&Re task, respectively. The best performance of each model under each task is highlighted in bold.

The leftmost displays the source and reference images. The first row shows model outputs before fine-tuning, the second row presents outputs after fine-tuning. The Weighted-Ref-VIEScore for each generated result is annotated in the corner. MICo-150K demonstrates strong robustness: BLIP-3o and Lumina-DiMOO acquire MICo capability from scratch; the emergent MICo abilities of BAGEL and Qwen-Image are significantly strengthened; OmniGen2 achieves further improvement on top of its already strong performance.











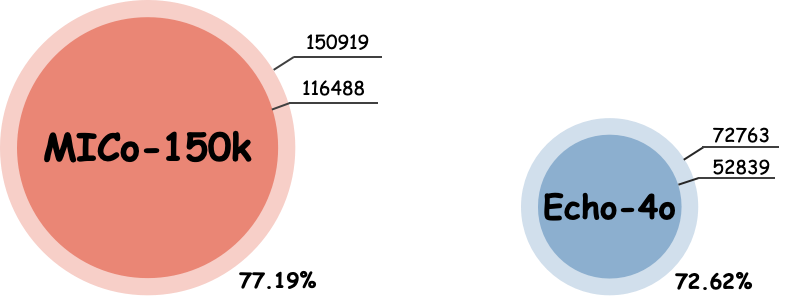
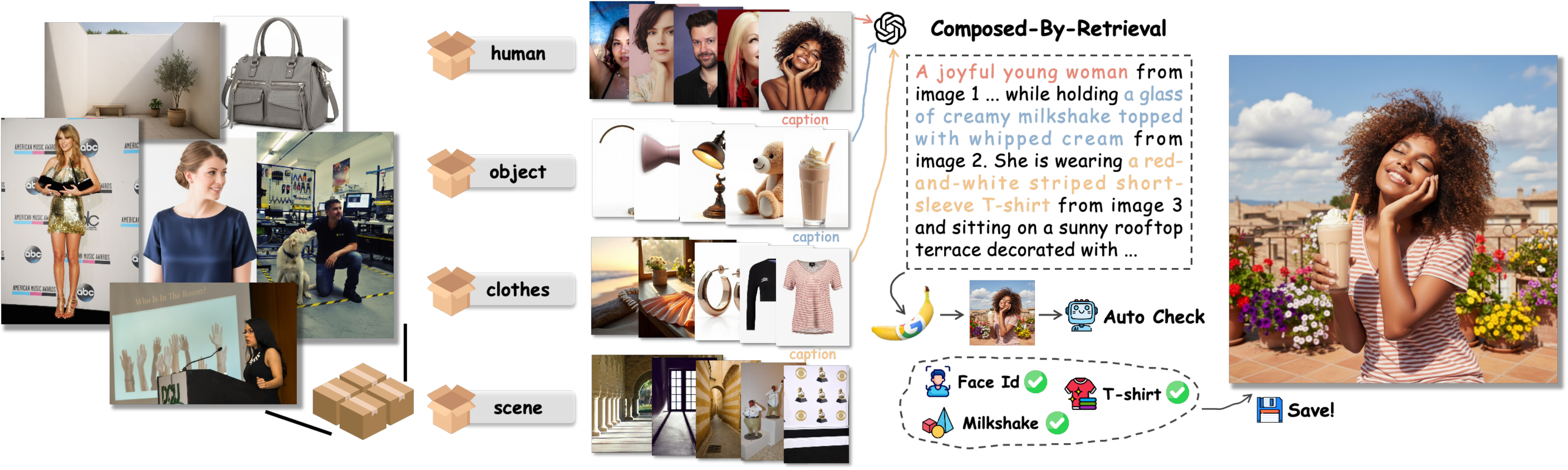
 Data Analysis
Data Analysis